

EKC 2.0记忆系统设计与实践:从用户认知到经验沉淀的完整方案
一、为什么需要智能体记忆
想象这样一个场景:你已经是第三次打开和 AI 助手的对话窗口了。每一次,你都不得不重新说一遍:“我是产品经理,我们团队在做一个电商平台,技术栈用的是 Next.js 加 FastAPI。“AI 每次都礼貌地回应:“好的,了解了!“——但下次对话,它又会像第一次见面一样,对你一无所知。这种体验,就像和一条金鱼对话:它的记忆只有当前这一轮,上一秒发生的事情,下一秒就忘得干干净净。这并非 AI 模型本身”笨”——事实上,大语言模型的推理能力已经非常强大。问题的根源在于无状态设计:传统的 AI 对话系统将每次交互视为独立事件,对话结束后,上下文随即清空。模型没有任何机制来记住”你是谁”、“你说过什么”、“上次我们讨论到了哪里”。
人类之所以能够进行流畅的协作,很大程度上依赖于记忆。认知科学告诉我们,人脑的记忆系统是分层的:短期记忆(工作记忆)帮助我们在当前对话中保持连贯;长期记忆则分为陈述性记忆(记住事实和事件)和程序性记忆(记住怎么做事)。正是这套分层体系,让我们能够在多次交互中不断积累对一个人、一个项目的理解。
那么,如果我们要打造一个真正”懂你”的 AI 智能体,就必须为它设计一套类似的记忆系统。这套系统需要回答四个核心问题:
1. 你是谁? —— 智能体需要记住用户的基本信息和偏好
2. 你说过什么?—— 智能体需要跨会话记住用户表达过的重要内容
**3. 世界是什么样的? **—— 智能体需要积累关于外部实体(人物、项目、概念)的知识
4. 我学到了什么?—— 智能体需要从反复交互中提炼出可复用的经验
在 EKC 2.0 中,我们正是围绕这四个问题,设计并实现了一套完整的智能体记忆系统。它包含四种记忆类型——UserProfile(用户画像)、UserMemory(用户记忆)、EntityMemory(实体记忆)和 LearnedKnowledge(学习知识)——它们各司其职、协同工作,让 AI 智能体从一条”金鱼”蜕变为一个真正能陪伴你成长的助手。
接下来,本文将从概念到实现、从架构到细节,带你全面了解这套记忆系统是如何工作的。无论你是 AI 产品经理、后端开发者,还是对智能体技术感兴趣的读者,都能从中获得清晰的认知。
二、概念铺垫:智能体记忆的分类体系
在深入 EKC 2.0 的具体实现之前,我们需要先建立一套认知框架——智能体的记忆都有哪些种类?它们之间有什么区别?理解了这些,后面的技术细节就会变得水到渠成。
2.1 从认知科学说起
人类大脑的记忆系统经过数百万年的进化,形成了精密的分层结构。认知科学将长期记忆分为三大类:
语义记忆(Semantic Memory):存储事实和概念性知识,不依赖具体时间。比如你知道”北京是中国的首都”,但不需要记得是什么时候学到的。
情节记忆(Episodic Memory):存储与时间相关的具体事件。比如你记得”上周五的团队会议上,老板宣布了项目延期”。
程序记忆(Procedural Memory):存储”怎么做”的技能。比如你会骑自行车,但很难用语言完整描述这个过程。
智能体记忆系统的设计,正是从这些认知科学理论中汲取了灵感。不过,AI 的记忆和人脑记忆有一个本质区别:AI 的记忆必须被显式设计和实现,而不是自然涌现的。因此,我们需要从多个维度来对记忆进行分类。
2.2 智能体记忆的四个维度
维度一:作用域(Scope)——这是谁的记忆?
有些记忆是属于特定用户的——比如”张三喜欢简洁的回答风格”,这只和张三有关。另一些记忆则是全局共享的——比如”我们团队统一使用 TypeScript 严格模式”,这对所有用户都有价值。前者是用户级记忆,后者是全局级记忆。
维度二:生命周期(Lifetime)——记忆能保持多久?
有些记忆只在当前会话内有效——比如”用户在这轮对话中提到要调试一个 bug”,对话结束后就不再重要。另一些记忆则需要跨会话持久化——比如用户的姓名和角色,今天记住的,明天打开新对话时也应该还在。
维度三:结构化程度(Structure)——记忆怎么存?
记忆的存储形式差异很大。用户的姓名和职位适合用结构化字段(像数据库表的一行)来存储。用户在对话中提到的各种偏好则更适合用自由文本(一段段自然语言笔记)。而那些需要通过语义相似度来检索的知识,则需要向量嵌入(将文本转化为数学向量,支持模糊搜索)。
维度四:触发方式(Trigger)——记忆是怎么产生的?
记忆可以在每次对话后自动提取系统静默分析对话内容并存储),也可以由 Agent 主动判断是否值得记录,甚至可以由 Agent 提议后等待用户确认再保存。不同的场景适合不同的触发方式。
2.3 EKC 2.0 四种记忆总览
有了上面的分类框架,我们就可以清晰地定位 EKC 2.0 中的四种记忆类型了:

可以看到,这四种记忆从不同角度覆盖了智能体需要”记住”的所有信息:UserProfile 和 **UserMemory **聚焦于用户本身,一个记结构化身份,一个记非结构化观察;EntityMemory 将视野扩展到用户提到的外部世界;LearnedKnowledge则更进一步,从具体事实中抽象出可复用的知识。
它们之间是”金字塔”关系:底层是具体、细粒度的信息(画像和记忆),往上是更宏观的世界知识和经验总结。接下来,我们就来看看 EKC 2.0 是如何在技术架构上承载这四种记忆的。
三、架构总览:EKC 2.0 记忆系统全景
在理解了记忆的分类体系后,让我们把目光聚焦到 EKC 2.0 的技术实现上。EKC 2.0 的记忆系统采用了清晰的三层架构,每一层各司其职,彼此解耦。
3.1 三层架构
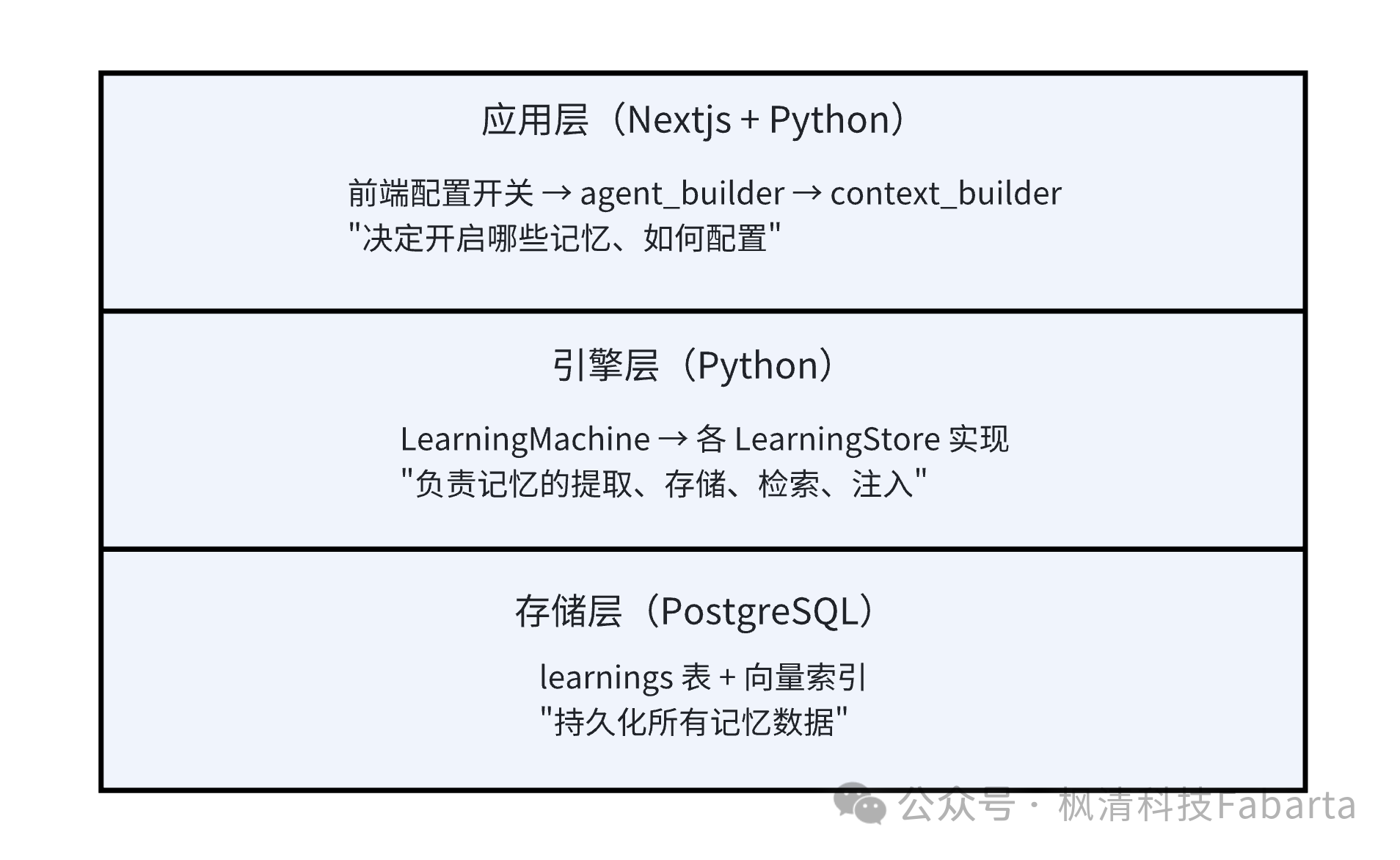
应用层负责”策略决策”——根据前端用户的配置(是否开启记忆、开启哪些类型),组装记忆系统的参数并注入到 Agent 中。
引擎层负责”执行逻辑”——记忆的提取算法、上下文注入格式、工具调用协议等核心能力都在这一层实现。
存储层是 PostgreSQL 数据库,负责”数据持久化”——所有记忆最终都以结构化数据的形式存入数据库,支持跨会话、跨设备的持久访问。
3.2 核心组件:LearningMachine
整个记忆系统的”大脑”是 LearningMachine(学习机器)。它扮演着总调度器的角色,统一协调所有记忆存储的读写操作。
LearningMachine 提供四个核心 API:
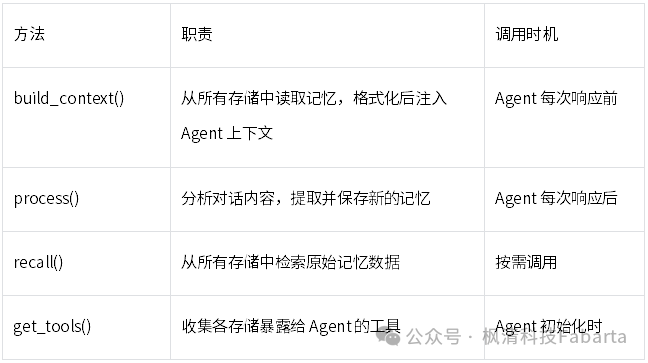
每一种记忆类型都对应一个 LearningStore(学习存储),它们通过统一的协议接口与 LearningMachine 交互。这种设计类似于”插件系统”——你可以按需启用或禁用某种记忆类型,而不影响其他部分。
3.3 EKC 2.0 的应用层方案
那么,EKC 2.0 是如何驱动这套引擎的呢?
EKC 2.0 采用了配置驱动的方式来管理记忆系统。整体流程如下:
1. **前端配置面板:**用户在 Agent 配置页面中,可以独立开关每一种记忆类型(用户记忆、用户画像等),灵活控制 Agent 的记忆能力范围
- **配置解析与组装:**后端的上下文构建模块接收前端传入的配置,根据开关状态按需组装 `LearningMachine` 实例——只有明确启用的记忆类型才会被注册到引擎中
3. **注入 Agent:**组装好的 LearningMachine 作为构造参数注入 Agent 实例,Agent 即具备了完整的记忆读写能力
这种方案的核心优势是业务层与引擎层完全解耦:
• EKC 2.0 只关心”开启哪些记忆”,不需要了解记忆提取的具体算法
• 引擎只关心”收到了什么配置”,不需要感知上层业务逻辑
• 新增记忆类型时,只需在配置组装环节增加对应条目,无需改动框架或存储层
这也意味着,未来扩展** EntityMemory**(实体记忆)或 LearnedKnowledge(习得知识)等新类型时,架构无需重构——整个设计是面向扩展开放的。
了解了整体架构,接下来我们深入每一种记忆类型的内部实现。
四、记忆类型的内部实现
4.1 UserProfile:“你是谁”
4.1.1 设计定位
UserProfile 是整个记忆系统中最”稳定”的一层。它记录的是用户的身份类信息——姓名、昵称,以及其他通过扩展 Schema 定义的结构化字段。这些信息几乎不会频繁变化,一旦记住就长期有效。
你可以把它想象成通讯录里的名片:上面只有最核心的几行字,但每次见面前瞄一眼,就能叫对人名、用对称呼。
4.1.2 核心特征

4.1.3 存储结构
UserProfile 使用预定义的 Schema 来存储数据。默认 Schema 包含 name 和 preferred_name 两个字段,但可以通过自定义 Schema 扩展更多字段。与 UserMemory 的自由文本不同,UserProfile 的每个字段都有明确的语义。
Python
@dataclass
class UserProfile:
user_id: str
name: Optional[str] = None
preferred_name: Optional[str] = None # 可通过自定义 Schema 扩展更多字段
这种设计的好处是:结构化字段可以被精确地查询和更新,不会出现”存了但找不到”的问题。
4.1.4 写入机制
UserProfile 的写入有两条路径:
路径一:自动提取(ALWAYS 模式)
在每次对话结束后,系统会自动分析对话内容,提取用户显式陈述的身份信息。核心流程如下:
1. 将对话内容转换为文本
2. 从数据库加载当前用户的已有 Profile
3. 构造一组提取工具(update_profile)和系统提示词
4. 调用 LLM 分析对话,判断是否有需要更新的字段
5. 如果 LLM 决定调用 update_profile,则保存到数据库
提取时的系统提示词会告诉 LLM 几条关键规则:
- 只保存用户显式陈述的信息,不做推理
• 如果已有字段值没变,不重复保存
• 如果对话中没有任何身份信息,什么都不做
路径二:Agent 主动调用(AGENTIC 模式)
当配置为 AGENTIC 模式时,系统会向 Agent 注入一个 update_profile 工具。Agent 可以在对话过程中主动判断用户是否透露了身份信息,并即时更新 Profile。
Python
Agent 在对话中检测到用户身份信息后调用update_profile(name="Sarah", preferred_name="Saz")4.1.5 读取与上下文注入
当 Agent 开始响应前,LearningMachine . build _ context () 会调用 UserProfileStore . recall (user _ id =…) 从数据库读取 Profile,然后通过 build_context() 格式化为如下形式注入到系统提示词中:
XML
<user_profile>
Name: Sarah
Preferred Name: Saz
<profile_application_guidelines>
Apply this knowledge naturally - respond as if you inherently know this information,
exactly as a colleague would recall shared history without narrating their thought process.
- Use profile information to personalize responses appropriately
- Never say "based on your profile" or "I see that" - just use the information naturally
- Current conversation always takes precedence over stored profile data
</profile_application_guidelines></user_profile>注意其中的”应用准则”部分——它明确告诉 Agent 要自然地使用这些信息,而不是声明”根据你的资料我知道你叫 Sarah”。这是一个重要的用户体验设计:好的记忆应该像人类同事那样,不需要每次都解释”我为什么知道这个”。
4.1.6 小结
UserProfile 虽然是最简单的记忆类型,但它解决了一个基础问题:让 Agent 知道它在和谁说话。有了这层基础,Agent 才能提供”个性化”而非”通用”的响应。
4.2 UserMemory:“你说过什么”
4.2.1 设计定位
如果说 UserProfile 是一张名片,那么 UserMemory 就是一本私人笔记本。它记录的是关于用户的非结构化观察——偏好、习惯、正在做的事、沟通风格等——这些信息不适合用固定字段来表达,但对于提供个性化体验至关重要。比如:“用户是 Stripe 的高级工程师,正在做支付基础设施迁移”、“偏好简洁直接的回答风格”——这类信息无法塞进 name 或 preferred_name 字段,但如果 Agent 能记住这些,下次对话的起点就完全不同。
4.2.2 核心特征
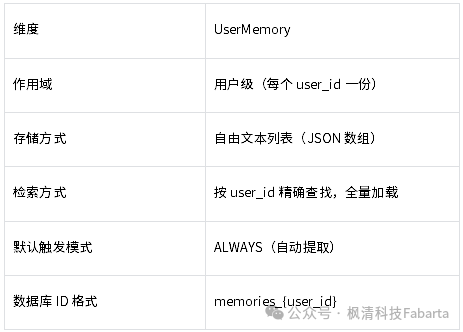
4.2.3 存储结构
UserMemory 的数据结构是一个记忆条目的列表,每条记忆都是一段自然语言描述:
JSON{
"memories": [
{
"id": "a1b2c3d4",
"content": "Senior engineer at Stripe, working on payment infrastructure",
"source": "User: I'm a senior engineer at Stripe...",
"added_by_agent": "agent-001"
},
{
"id": "e5f6g7h8",
"content": "Prefers concise responses without lengthy explanations",
"source": "User: Can you skip the explanations and just give me the code?",
"added_by_agent": "agent-001"
}
]
}
每条记忆带有唯一 ID(用于后续更新和删除)、内容文本、来源摘录(对话片段的前 200 字符),以及审计信息。
4.2.4 写入机制:LLM 驱动的三操作模型
UserMemory 的写入是整个记忆系统中最复杂也最精巧的部分。它不是简单的”存储用户说的话”,而是一个 LLM 驱动的内容管理流程。
系统为提取模型提供了三个核心操作工具:

**为什么需要更新和删除? **这是一个关键设计决策。如果只有”新增”操作,记忆会随着时间不断膨胀,出现大量重复和过时信息。通过给 LLM 同时提供已有记忆列表和三种操作,系统能够:
- 当新信息扩展了已有记忆时 → 更新(而非新增一条类似的)
- 当已有记忆不再准确时 → 替换或删除
- 当信息确实全新时 → 新增
提取模型收到的系统提示词包含了详细的”记忆哲学”:
Plain Text
## Memory Philosophy
Think of memories as what a thoughtful colleague would remember:
- Their role and what they're working on
- How they prefer to communicate
- What matters to them and what frustrates them
## Consolidation Over Accumulation**Critical:
** Prefer updating existing memories over adding new ones.
- If new information extends an existing memory, UPDATE it
- If new information contradicts an existing memory, REPLACE it
- Quality over quantity: 5 great memories beat 20 mediocre ones
这套设计确保了记忆的”新陈代谢”——有增长、有淘汰、有整合,而不是无限膨胀。
4.2.5 读取与上下文注入
读取流程与 UserProfile 类似,但注入到上下文中的格式不同:
XML
<user_memory>
- Senior engineer at Stripe, working on payment infrastructure
- Prefers concise responses without lengthy explanations
- Currently migrating from REST to gRPC for internal services
<memory_application_guidelines>
Apply this knowledge naturally - respond as if you inherently know this information,
exactly as a colleague would recall shared history without narrating their thought process.
- Selectively apply memories based on relevance to the current query
- Never say "based on my memory" or "I remember that"
- Current conversation always takes precedence over stored memories
- Use memories to calibrate tone, depth, and examples without announcing it
</memory_application_guidelines>
</user_memory>
注意一个细节:选择性应用。指令明确告诉 Agent 只在相关时使用记忆——如果用户问的是天气,就不需要提及他是工程师。这避免了”过度使用记忆”导致的诡异感。
4.2.6 Agent 工具模式
除了后台自动提取,UserMemory 还支持 AGENTIC 模式下向 Agent 暴露 update_user_memory 工具。Agent 可以在对话中主动判断”这个信息值得记住”:
Python
def update_user_memory(task: str) -> str:
"""Save or update information about this user for future conversations.
Good examples:
- "User is a senior engineer at Stripe working on payments"
- "Prefers concise responses without lengthy explanations"
- "Update: User moved from NYC to London"
- "Remove the memory about their old job at Acme"
"""
这个工具的设计非常灵活:task 参数是自然语言描述,可以是新增、更新、甚至删除的指令。系统内部会将其转发给提取模型来执行实际的记忆操作。
4.2.7 与 UserProfile 的分工
UserProfile 和 UserMemory 的区别可以用一句话概括:
UserProfile 记”你是谁”(身份),UserMemory 记”你是什么样的人”(特征)。
具体分工:
• 名字、昵称 → UserProfile(结构化,可精确查询)
• 职业、偏好、正在做的事 → UserMemory(非结构化,语义丰富)
两者共同构成了 Agent 对用户的完整认知,缺一不可。
4.2.8 小结
UserMemory 是让 Agent 从”有礼貌的陌生人”变成”了解你的同事”的关键。它的精妙之处不在于”能记住东西”——任何数据库都能做到——而在于 LLM 驱动的整合机制:自动判断什么值得记、什么需要更新、什么应该淘汰,让记忆始终保持精炼和准确。
4.3 EntityMemory:“世界是什么样”
4.3.1 设计定位
前两种记忆都聚焦于用户本身——UserProfile 记”你是谁”,UserMemory 记”你说过什么”。但用户在对话中谈论的远不止自己:他们会提到自己的公司、同事、正在评估的技术方案、合作的客户……EntityMemory 就是用来记住这些外部实体的。它像一本百科全书——只不过里面收录的不是维基百科的内容,而是用户在对话中提到的那些人、公司、项目和产品。
一句话区分:
**• UserProfile / UserMemory **= 关于”你”的知识
• EntityMemory= 关于”你提到的一切”的知识
4.3.2 核心特征
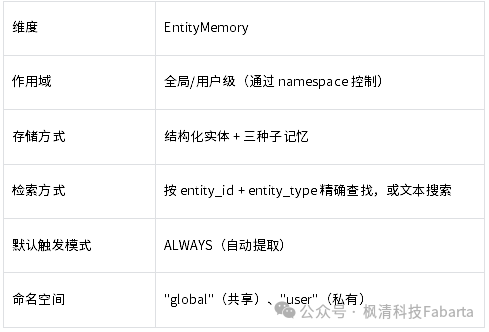
4.3.3 三层记忆模型
EntityMemory 最独特的设计是它的三层子记忆结构,直接映射到认知科学的经典分类:
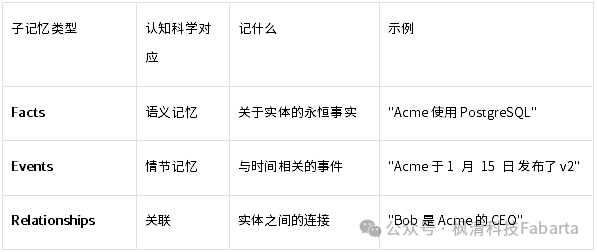
4.3.4 存储结构
每个实体在数据库中存储为一个完整的 JSON 文档:
JSON
{
"entity_id": "acme_corp",
"entity_type": "company",
"name": "Acme Corporation",
"description": "Enterprise SaaS startup in the fintech space",
"properties": {"industry": "fintech", "stage": "Series A"},
"facts": [
{"id": "f1", "content": "Uses PostgreSQL and Redis for data layer"},
{"id": "f2", "content": "Engineering team based in Austin"}
],
"events": [
{"id": "e1", "content": "Launched v2.0 with ML features", "date": "2025-01-15"},
{"id": "e2", "content": "Closed $50M Series B led by Sequoia", "date": "2024-Q3"}
],
"relationships": [
{"id": "r1", "entity_id": "bob_smith", "relation": "CEO", "direction": "incoming"},
{"id": "r2", "entity_id": "beta_inc", "relation": "competitor_of", "direction": "outgoing"}
],
"namespace": "global",
"created_at": "2025-01-20T10:30:00Z",
"updated_at": "2025-02-15T14:22:00Z"
}数据库 ID 的构造格式为 entity_memory_{entity_id}_{entity_type}_{namespace},确保同一实体在不同命名空间下可以有独立的记录。
4.3.5 命名空间:共享与隔离
EntityMemory 引入了**命名空间(Namespace)**概念来控制记忆的共享范围:
- global(默认):组织内所有人共享。张三在对话中提到的”Acme 公司用 PostgreSQL”,李四也能看到。
- user:私有。只有创建者能访问,适合存储个人视角的解读。
- 自定义字符串(如 “sales_team”):团队级共享。
这解决了一个实际问题:有些关于外部实体的信息是普适的(公司的技术栈),有些则带有个人视角(“我觉得这个客户很难合作”)。命名空间让两类信息各得其所。
4.3.6 Agent 工具集
当配置为 AGENTIC 模式时,EntityMemory 向 Agent 暴露了一套丰富的工具:

这些工具的 docstring 设计得非常详细,包含了大量示例和判断标准。比如 add_fact 的文档会告诉 Agent:
Plain Text
Good facts (timeless, descriptive):
- "Uses PostgreSQL and Redis for their data layer"
- "Headquarters in San Francisco"
Not facts (use events instead):
- "Launched v2.0 last month" → This is an EVENT
- "Just closed Series B" → This is an EVENT
这种设计确保 Agent 能正确区分 Fact 和 Event,不会把时效性信息错误地存为永恒事实。
4.3.7 搜索机制
EntityMemory 的搜索是全文匹配式的——查询词会与实体的名称、描述、属性、事实内容、事件内容和关系对象逐一比对:
Python
def _matches_query(self, content, query):
# 依次检查:name → entity_id → description → properties → facts → events → relationships
...
虽然不是向量语义搜索(那是 LearnedKnowledge 的方式),但对于实体记忆来说,精确匹配已经足够——你通常是按名字或关键词来查找一个实体。
4.3.8 自动提取(ALWAYS 模式)
在 ALWAYS 模式下,系统会在对话结束后自动分析对话内容,识别出提到的实体并提取相关信息。提取模型会收到对话文本和一组操作工具(create_entity、add_fact、add_event、add_relationship),然后判断是否有值得保存的实体信息。
与 UserMemory 类似,提取模型也会遵循”整合优先于堆积”的原则——如果实体已存在,优先更新而非重复创建。
4.3.9 小结
EntityMemory 将 Agent 的认知从”只了解用户”扩展到了”了解用户谈论的世界”。它的三层子记忆模型(Facts/Events/Relationships)提供了丰富的知识表达能力,而命名空间机制则解决了多用户环境下知识共享与隔离的平衡问题。当一个 Agent 不仅记得”你是谁”,还记得”你提到的那个项目后来怎么样了”——这才是真正有用的长期记忆。
4.4 LearnedKnowledge:“我学到了什么”
4.4.1 设计定位
前三种记忆——UserProfile、UserMemory、EntityMemory——都在记录具体的事实:你叫什么、你喜欢什么、某个公司用什么技术栈。而 LearnedKnowledge 站在更高的抽象层次上:它记录的是从具体经验中提炼出的可复用知识。打个比方:如果 UserMemory 记住了”用户上次调试 PostgreSQL 连接超时花了 3 小时”,那么 LearnedKnowledge 应该记住的是”排查数据库连接超时时,应该先检查连接池耗尽,再排查网络问题”。前者是经历,后者是经验。这正是 LearnedKnowledge 的核心价值:让 Agent 从反复交互中变得更聪明,而不仅仅是更了解你。
4.4.2 核心特征

4.4.3 与其他记忆类型的根本区别
LearnedKnowledge 有两个与前三种记忆截然不同的设计选择:
**区别一:向量存储而非关系存储。**UserProfile、UserMemory、EntityMemory 都存在 PostgreSQL 的 learnings 表中,按 ID 精确查找。而 LearnedKnowledge 存在向量数据库(Knowledge Base)中,通过语义相似度搜索。这是因为知识的检索场景是模糊的——当用户问”怎么优化 API 性能”时,系统需要找到语义上相关的经验,而不是按某个 ID 精确匹配。
区别二:默认 AGENTIC 而非 ALWAYS。 前三种记忆都默认在对话后自动提取(ALWAYS 模式),而 LearnedKnowledge 默认由 Agent 主动判断是否值得保存(AGENTIC 模式)。这是因为”可复用知识”比”具体事实”更需要判断力——不是每段对话都能产出有价值的经验,强制提取反而会导致知识库被低质量内容淹没。
4.4.4 存储结构
每条 Learning 包含四个核心字段:
Python
@dataclass
class LearnedKnowledge:
title: str # 简洁的可搜索标题
learning: str # 具体的洞察或经验
context: str # 适用场景
tags: List[str] # 分类标签
namespace: str # 共享范围
created_at: str # 创建时间
保存时,这些字段会被序列化为文本,通过 Knowledge Base 的 TextReader 转化为向量嵌入并存入向量数据库。检索时,用户的问题也会被转化为向量,通过余弦相似度找到最相关的知识条目。
4.4.5 双工具设计
LearnedKnowledge 向 Agent 暴露两个工具,形成”先搜后存”的工作流:
**4.4.5.1 **search_learnings —— 搜索已有知识
Pythondef search_learnings(query: str, limit: int = 5) -> str:
"""Search for relevant insights in the knowledge base.
ALWAYS call this:
1. Before answering questions about best practices or recommendations
2. Before saving a new learning (to check for duplicates)
"""
这个工具的使用时机被明确定义:当用户询问最佳实践、建议、方法论等”知识性”问题时,Agent 应该先搜索已有知识,再结合搜索结果回答。这确保了过去积累的经验能被真正利用。
4.4.5.2 save_learning —— 保存新知识
Plain Text
Python
def save_learning(
title: str,
learning: str,
context: Optional[str] = None,
tags: Optional[List[str]] = None,
) -> str:
"""Save a reusable insight or organizational context.
IMPORTANT: You MUST call search_learnings first to check for duplicates.
"""
保存前必须先搜索——这个约束被写进了工具文档中,确保不会产生重复知识
4.4.6 触发策略:AGENTIC vs ALWAYS vs PROPOSE
LearnedKnowledge 支持三种触发模式,各有适用场景:
AGENTIC 模式(默认):Agent 在对话过程中主动决定是否保存。系统注入的提示词定义了四条关键规则:
1. 知识性问题先搜索:在回答建议、最佳实践类问题前,先搜索知识库
- 保存前先搜索:避免重复
3. 用户显式要求必须保存:当用户说”记住这个”时,必须执行
4. 组织级信息必须保存:团队目标、约束、策略等共享上下文同时,提示词也明确了不应保存的内容:原始事实(那是 EntityMemory 的职责)、个人偏好(那是 UserMemory 的职责)、常识、一次性答案。
**ALWAYS 模式:**对话后自动提取。系统会将对话文本和已有知识摘要一起发送给提取模型,由模型判断是否有值得提炼的经验。与手动 AGENTIC 模式相比,ALWAYS 模式更适合”被动积累”的场景。
**PROPOSE 模式:**Agent 提出保存建议,但不立即执行,而是在回复末尾展示提议内容,等待用户确认后再保存:
Markdown
**Proposed Learning**
**Title:** Debugging intermittent PostgreSQL connection timeouts
**Context:** When diagnosing database connectivity issues
**Insight:** Check for connection pool exhaustion before investigating network issues.
Save this to the knowledge base? (yes/no)PROPOSE 模式在”知识质量”和”用户控制”之间取得了巧妙的平衡——Agent 负责发现,用户负责审批。
4.4.7 上下文注入
当 Agent 开始响应时,系统会用当前用户消息作为查询词进行语义搜索,将最相关的已有知识注入上下文:
XML<relevant_learnings>
Prior insights that may help with this task:
1. **Debugging intermittent PostgreSQL connection timeouts**
Check for connection pool exhaustion before investigating network issues.
_Context: When diagnosing database connectivity issues_
_Tags: postgresql, performance_
2. **API rate limiting best practices**
Implement exponential backoff with jitter for retry logic.
_Context: When building API clients_
Apply these naturally if they're relevant to the current request.
Your current analysis and the user's specific context take precedence.
</relevant_learnings>
注意最后一句:“你当前的分析和用户的具体上下文优先”——这防止了 Agent 盲目套用过去的经验,而忽视当前对话的特殊性。
4.4.8 命名空间与知识共享
与 EntityMemory 类似,LearnedKnowledge 也支持命名空间:
- global(默认):知识在所有用户间共享。一个人发现的最佳实践,所有人都能受益。
- user:私有知识,只有创建者能搜索到。
- 自定义字符串:团队级共享。在保存时,命名空间会作为元数据写入向量数据库,搜索时通过过滤条件实现范围限定。
4.4.9 小结
LearnedKnowledge 是记忆系统金字塔的顶层。它不满足于记住”发生了什么”,而是追求提炼出”学到了什么”。通过向量语义搜索、三种灵活的触发模式、以及”先搜后存”的去重机制,它让 Agent 能够随着使用时间的增长变得越来越”有经验”——这正是从”工具”到”助手”的关键跨越。
4.5 记忆的生命周期
前面四节拆解了每种记忆”长什么样”,这一章则要回答另一个问题:记忆是怎么流动的?从用户发送一条消息,到记忆被写入、被检索、被维护——整个生命周期由三个阶段构成。
4.5.1 写入流程:Process
“写入”发生在 Agent 完成一次响应之后。LearningMachine.aprocess() 被调用,它会依次遍历所有已注册的 Store,将对话消息传递给每个 Store 的 aprocess() 方法:
Python
async def aprocess(self, messages, user_id, session_id, namespace, **kwargs):
for name, store in self.stores.items():
await store.aprocess(
messages=messages,
user_id=user_id,
session_id=session_id,
namespace=namespace,
**kwargs,
)
每个 Store 根据自身的 mode 配置决定是否执行提取:
- ALWAYS 模式:无条件执行提取。Store 会将对话文本和已有数据一起发送给一个专用的 LLM(提取模型),由 LLM 判断是否需要增、改、删。
- AGENTIC 模式:跳过自动提取。记忆的写入完全由 Agent 在对话过程中通过工具调用完成(如 `save_learning`、`update_user_memory`)。
- PROPOSE 模式:由 Agent 在回复中提出建议,用户确认后再写入。
一个关键的架构决策是:**提取模型和主对话模型是独立的调用。**提取使用的是 `deepcopy(self.model)` 得到的模型副本,这意味着提取操作不会影响主对话的上下文,也不会消耗主对话的 token 预算。每种记忆类型的提取都有自己专门设计的系统提示词,引导 LLM 按照正确的规范进行信息抽取。以 UserMemory 为例,完整的写入链条是:
Plain Text
对话结束
→ LearningMachine.aprocess()
→ UserMemoryStore.aprocess()
→ 检查 mode == ALWAYS?是 → 继续
→ 获取对话文本 (get_conversation_text)
→ 从数据库加载已有记忆
→ 构造提取工具 (add_memory, update_memory, delete_memory)
→ 构造系统提示词(含已有记忆列表)
→ 调用提取模型(独立的 LLM 调用)
→ 模型通过工具调用执行增/改/删
→ 数据持久化到数据库
4.5.2 读取流程:Build Context
“读取”发生在 Agent 开始生成响应之前。LearningMachine.abuild_context() 被调用,它首先通过 arecall() 从所有 Store 中检索数据,然后通过 _format_results() 将数据格式化为上下文字符串,最终注入到 Agent 的系统提示词中。
Python
async def abuild_context(self, user_id, session_id, message, **kwargs):
# Step 1: 从所有 Store 中检索
results = await self.arecall(user_id=user_id, message=message, **kwargs)
# Step 2: 格式化为上下文字符串
return self._format_results(results)
arecall() 的内部逻辑是遍历所有 Store,调用每个 Store 的 arecall() 方法:
Python
async def arecall(self, user_id, session_id, message, **kwargs):
results = {}
for name, store in self.stores.items():
result = await store.arecall(
user_id=user_id,
session_id=session_id,
message=message, # 当前用户消息
query=message, # LearnedKnowledge 用作语义搜索的查询词
**kwargs,
)
results[name] = result
return results
注意 message 参数的双重角色:对于 UserProfile 和 UserMemory,它没有实际用途(它们按 user_id 精确查找);但对于 LearnedKnowledge,当前消息会作为语义搜索的查询词,用来从向量数据库中找到最相关的已有知识。
_format_results() 会依次调用每个 Store 的 build_context(data) 方法。每种 Store 有自己的格式化逻辑,输出用 XML 标签包裹的上下文片段。最终,所有片段通过双换行连接,拼接成完整的记忆上下文:
Plain Text<user_profile>
Name: Sarah
Preferred Name: Saz
...
</user_profile>
<user_memory>
- Senior engineer at Stripe
- Prefers concise responses
...
</user_memory>
<relevant_learnings>
1. **Debugging PostgreSQL connection timeouts**
Check for connection pool exhaustion first.
...
</relevant_learnings>
这段上下文会被注入到 Agent 的系统提示词中,Agent 在生成响应时就能”看到”所有相关的记忆。
4.5.3 维护机制:Curator
记忆不是写入后就永远不变的。随着时间推移,记忆会过时、重复、膨胀。Curator是 LearningMachine 提供的记忆维护模块,负责记忆的”新陈代谢”。
Curator 目前提供两个核心操作:
**修剪(Prune):**按时间和数量淘汰记忆。
Python
删除 90 天以前的记忆,最多保留 100 条removed = learning.curator.prune( user_id="alice", max_age_days=90, max_count=100,)修剪遵循”保新去旧”的原则:先按 created_at 时间戳过滤,再按数量上限截取最新的记录。对于没有时间戳或时间戳格式异常的记忆,采取保守策略——保留而非删除。
**去重(Deduplicate):**移除内容重复的记忆。
Python
移除内容相同或几乎相同的重复记忆
deduped = learning.curator.deduplicate(user_id="alice")去重使用标准化后的文本比对:将内容转为小写、去除标点和多余空格后进行完全匹配。这能有效处理大小写差异、标点不同但内容相同的重复条目。
需要说明的是,Curator 并不是自动运行的后台任务——它是一个按需调用的维护 API。应用层可以根据业务需求决定何时触发维护,比如定期清理、或在记忆数量超过阈值时触发。
4.5.4 全流程串联
把三个阶段串联起来,一次完整的对话中记忆系统的参与过程如下:
Plain Text
用户发送消息
↓
[读取] LearningMachine.abuild_context()
→ 从各 Store 检索记忆
→ 格式化并注入系统提示词
↓
Agent 生成响应(系统提示词中包含记忆上下文)
→ Agent 可能通过工具调用写入记忆(AGENTIC 模式)
↓
[写入] LearningMachine.aprocess()
→ 各 Store 按 mode 执行自动提取(ALWAYS 模式)
→ 提取模型分析对话,执行增/改/删
↓
[维护] Curator(按需触发)
→ 修剪过期记忆
→ 去除重复记忆这个流程的设计有一个重要特点:读取在前,写入在后。Agent 先”回忆”已有的记忆来生成更好的响应,响应结束后再从本次对话中”学习”新的记忆。这确保了 Agent 不会在同一轮对话中使用刚刚提取的(可能不准确的)新记忆。
4.6 LearningMode:四种触发策略
在前面的章节中,我们多次提到”ALWAYS 模式”、“AGENTIC 模式”等术语。这一章集中讲清楚:记忆的写入可以被什么方式触发?不同的触发策略背后是怎样的设计权衡?
4.6.1 四种模式总览
LearningMode 是一个枚举类型,定义了四种记忆的触发策略:

4.6.2 ALWAYS:静默的后台提取
ALWAYS 是 UserProfile、UserMemory 和 EntityMemory 的默认模式。它的设计哲学是:**用户不需要操心记忆管理——系统自动处理一切。**每次 Agent 响应完成后,系统静默地将对话内容发送给一个专用的提取模型。提取模型分析对话,决定是否有值得记录的信息,然后通过工具调用(add_memory、update_profile 等)将结果写入数据库。整个过程对用户完全透明。
**优点:**零用户负担,记忆覆盖率高(不会遗漏)。
**代价:**每次对话都会产生额外的 LLM 调用(提取模型),即使对话中没有值得记录的内容。同时,自动提取可能偶尔”误判”——将不重要的信息存为记忆。但通过精心设计的提示词和”整合优先”的策略,这些问题在实践中得到了有效控制。
4.6.3 AGENTIC:Agent 的主动判断
AGENTIC 是 LearnedKnowledge 的默认模式。它的设计哲学是:**让最了解上下文的角色来决定——Agent 自己。**在这种模式下,系统不会在对话后执行自动提取,而是向 Agent 注入记忆工具(如 search_learnings、save_learning)。Agent 在对话过程中根据情况判断:
• 用户问了一个建议类问题?→ 先搜索已有知识
• 发现了一个有价值的洞察?→ 主动保存
• 用户说”记住这个”?→ 必须保存
AGENTIC 模式之所以适合 LearnedKnowledge,是因为”可复用知识”的提取需要较高的判断力。不是所有对话都能产出有价值的经验——如果像 ALWAYS 模式那样对每次对话都执行提取,知识库很容易被低质量内容淹没。
**优点:**知识质量高(经过 Agent 的判断过滤),不浪费 token 在无意义的对话上。
**代价:**依赖 Agent 的判断力——如果 Agent 遗漏了有价值的知识,就不会被保存。
4.6.4 PROPOSE:人机协作的审批模式
PROPOSE 模式是 AGENTIC 和 HITL 之间的折中方案。Agent 负责”发现”值得保存的知识,但不直接保存,而是以结构化的格式在回复末尾展示提议:
Markdown
Proposed Learning
Title: PostgreSQL JSONB indexing for nested queries
Context: When query performance degrades on JSONB columns
Insight: Use GIN index with jsonb_path_ops for 3-5x improvement on containment queries.
Save this to the knowledge base? (yes/no)
只有当用户回复”yes”后,Agent 才会调用 `save_learning` 工具执行保存。
**优点:**知识质量最高(经过双重审核),用户对记忆系统有完全的控制感。
**代价:**增加了交互步骤,用户需要主动参与确认。如果用户频繁忽略提议,积累效率会很低。
4.6.5 各记忆类型的模式支持矩阵
并非所有记忆类型都支持所有模式:
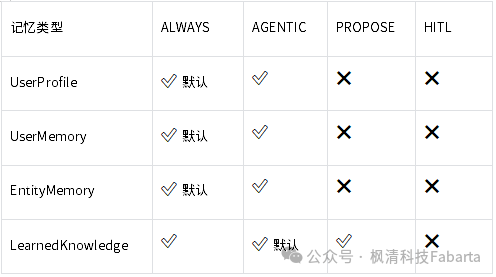
UserProfile 和 UserMemory 不支持 PROPOSE 和 HITL 模式,因为它们记录的是客观事实(用户的名字、偏好),不需要用户额外审批。而 LearnedKnowledge 支持 PROPOSE,因为”经验”的价值本身就带有主观性,用户审批能显著提升质量。
4.6.6 设计哲学
四种模式的本质是在自动化程度和质量控制之间做选择:

EKC 2.0 的默认选择——UserProfile/UserMemory 用 ALWAYS,LearnedKnowledge 用 AGENTIC——在”零用户负担”和”知识质量”之间找到了一个务实的平衡点:日常的用户信息自动记录,不打扰用户;高价值的经验知识由 Agent 主动判断,避免低质量堆积。
4.7 记忆模式最佳实践
前面几章分别介绍了四种记忆类型的机制和触发策略。那么在真实的企业场景中,**什么时候该用哪种记忆?怎么组合才能达到最好的效果?**这一章基于 EKC 2.0 的生产实践,给出具体的选型建议。
4.7.1 UserProfile:高频交互的身份锚点
**适用场景:**用户每天都会与同一个 Agent 对话,且对话涉及称呼、身份等基础信息。
**典型案例:**企业内部的 IT 运维助手。员工第一次对话时提到”我是研发二组的张明”,UserProfile 自动提取姓名和称呼。此后每次对话,Agent 都能直接称呼”张明”,而不是反复问”请问您是?”。
**预期效果:**消除重复的身份确认环节,首轮对话即进入正题。由于 UserProfile 是结构化字段、按 user_id 精确查找,检索开销极低,适合作为所有记忆场景的基础层。
**配置建议:**UserProfile 使用 ALWAYS 模式自动提取,对话结束后静默完成,用户无感知。作为开销最低的记忆类型,建议所有需要多轮对话的 Agent 都默认开启。
4.7.2 UserMemory:长期服务的偏好积累
**适用场景:**Agent 需要”越用越懂你”——记住用户的沟通偏好、工作习惯、历史决策等非结构化信息。
**典型案例:**文档写作助手。用户在多次对话中分别提到”我喜欢简洁风格”、“我们团队用 Markdown 写文档”、“表格比文字好”。这些零散的偏好被 UserMemory 逐条积累,后续生成文档时自动应用——不需要用户每次重复说明。
**预期效果:**随着使用次数增加,Agent 的输出越来越贴合用户个人风格。UserMemory 的 LLM 驱动整合机制会自动合并重复信息(如”喜欢简洁”和”不要长篇大论”合并为一条),避免记忆膨胀。
**配置建议:**UserMemory 同样使用 ALWAYS 模式,适合所有需要”越用越懂你”的长期服务型 Agent。
4.7.3 EntityMemory:知识密集型的实体追踪
**适用场景:**对话频繁涉及外部实体(客户、项目、产品、系统等),且需要跨会话积累这些实体的事实、事件和关系。
**典型案例:**销售助理 Agent。销售人员在不同会话中陆续提到:“A 公司用的是 PostgreSQL”(事实)、“A 公司上周完成了 v2 上线”(事件)、“李总是 A 公司的 CTO”(关系)。EntityMemory 将这些信息归档到”A 公司”这个实体下,形成一张不断丰富的知识图谱。下次销售人员提到 A 公司时,Agent 能立刻调出完整的客户画像。
**预期效果:**Agent 具备对第三方实体的持续认知能力,不再局限于”只记得用户本人”。Facts / Events / Relationships 三层子结构让信息井然有序,检索时可以按实体 ID 精确定位。
**配置建议:**EntityMemory 使用 ALWAYS 模式自动提取,通过 `namespace` 控制共享范围——设为 `“global”` 则全组织共享同一份实体知识,设为 `“user”` 则每人维护私有图谱。适合团队协作场景选 global,个人助理场景选 user。
4.7.4 LearnedKnowledge:经验沉淀与复用
**适用场景:**Agent 在解决问题过程中产出了有复用价值的经验洞察,需要保存下来供未来类似问题参考。
**典型案例:**技术运维 Agent。某次排障过程中,Agent 和工程师一起发现”当 JSONB 列查询变慢时,用 GIN 索引配合 jsonb_path_ops 可以提升 3-5 倍性能”。这条经验通过 LearnedKnowledge 保存到向量数据库。下次其他工程师遇到类似的 JSONB 性能问题时,Agent 会通过语义搜索自动召回这条经验,直接给出建议。
**预期效果:**将团队的隐性知识显性化。与传统知识库不同,LearnedKnowledge 的写入和检索都由 Agent 驱动——写入时 Agent 判断什么值得保存(避免低质量堆积),检索时基于语义匹配(不依赖关键词命中)。
**配置建议:**默认使用 AGENTIC 模式,让 Agent 自主决定何时读写。对知识质量要求极高的场景(如医疗、法律),可切换为 PROPOSE 模式——Agent 提出保存建议,用户确认后才写入,确保每条知识都经过人工审核。
4.7.5 组合策略:从简单到完整
并非每个 Agent 都需要开启全部四种记忆。EKC 2.0 的建议是按需渐进:

每多开启一种记忆,都会带来额外的存储和 LLM 调用开销。对于只需要”记住用户名字”的简单场景,开一个 UserProfile 就够了——没必要搬出全套装备。
4.7.6 小结
四种记忆模式不是”越多越好”,而是”对症下药”。UserProfile 和 UserMemory 解决”认识用户”的问题,EntityMemory 解决”认识世界”的问题,LearnedKnowledge 解决”积累经验”的问题。在 EKC 2.0 中,通过前端开关和后端配置的组合,开发者可以为不同业务场景精确选择最合适的记忆组合,在用户体验和系统开销之间找到最优平衡。
4.8 总结与展望
4.8.1 回顾
本文从”为什么智能体需要记忆”这个问题出发,完整介绍了 EKC 2.0 记忆系统的设计与实现。让我们快速回顾核心要点:
四种记忆,各司其职:

**三层架构,各就各位:**应用层负责策略配置,引擎层负责核心逻辑,存储层(PostgreSQL + 向量数据库)负责持久化。
**生命周期,循环运转:**读取(Build Context)→ 响应 → 写入(Process)→ 维护(Curator),形成闭环。
4.8.2 设计原则
回顾整个系统的设计,有几条贯穿始终的原则值得提炼:
**1. 自然融入,而非刻意展示。**记忆系统的最高境界是用户感觉不到它的存在——Agent 只是”更懂你了”,而不是每次都宣布”根据我的记忆…”。这体现在所有 `build_context` 方法中的 application guidelines 设计上。
2. 整合优先于堆积。 无论是 UserMemory 的”更新已有记忆而非新增类似条目”,还是 LearnedKnowledge 的”保存前先搜索去重”,系统始终追求精炼的知识而非膨胀的数据。5 条高质量的记忆胜过 50 条重复的碎片。
**3. 分层递进,各取所需。 **从最简单的结构化字段(UserProfile),到自由文本(UserMemory),到富结构实体(EntityMemory),再到向量嵌入的经验知识(LearnedKnowledge)——四层记忆对应四种不同的信息类型,用最合适的存储和检索方式。
**4. 配置驱动,可插拔。**从前端的开关到后端的 Config 类,整个系统面向”按需启用”设计。不需要记忆时零开销,需要时一行配置即可开启。
4.8.3 未来方向
当前实现已经覆盖了记忆系统的核心能力,但仍有可以继续探索的方向:
**- EntityMemory 和 LearnedKnowledge 的前端集成:**目前 EKC 2.0 的前端开关只控制 UserProfile 和 UserMemory,EntityMemory 和 LearnedKnowledge 的前端配置是下一步的自然扩展。
**- 记忆的主动遗忘:**当前的 Curator 提供了基于时间和数量的修剪能力,但更智能的遗忘策略——比如基于使用频率衰减、语义去重——将进一步提升记忆质量。
**- 记忆的可解释性:**让用户能够查看、编辑、删除 Agent 对自己的记忆,增强信任感和控制感。
记忆系统的本质,是让 AI 从”每次都是初次见面”进化为”一个真正记得你的伙伴”。EKC 2.0 通过四种记忆类型的协同工作,迈出了这一步。而随着技术的持续演进,我们相信 AI 的记忆能力还将继续向着更自然、更智能、更值得信赖的方向发展